
Segmentering är på väg att bli en kritisk del av att säkra nätverk. I den här tekniska artikeln kommer jag att jämföra MPLS VPN med VRF-lite. Båda är metoder för att segmentera ett nätverk logiskt på L3 med VNs (VRF:er, virtual routing and forwarding).
För många år sedan när jag var ny inom nätverksteknik var jag lite rädd för ”MPLS”. Jag såg det som något vansinnigt komplicerat som bara tjänsteleverantörer använde för att på ett magiskt sätt koppla ihop stora företagsnätverk. När jag senare började lära mig mer om MPLS förstod jag att det mer handlade om min rädsla för det okända.
MPLS kan vara komplext! Men L3 MPLS VPN:er är ganska enkelt. Låt mig visa dig nedan vad jag menar.
MPLS VPN
Innan vi dyker in i MPLS VPNs rike av bits och bytes vill jag introducera den enkla nodtypologi jag kommer att använda här:

Först lite terminologi om du är ny inom MPLS:
- PE – Provider Edge router
- Gränssnitt med både MPLS-molnet och det vanliga segmenterade IP-nätverket. Denna nodtyp ansluter till alla MPLS-nodtyper.
- P – Provider router
- Finns i MPLS-molnet. Denna nod ansluter till andra P-routrar och PE-routrar.
- CE – Customer Edge router
- (används inte i det här inlägget)
- Kör vanlig IP och befinner sig utanför MPLS-molnet. Denna nod ansluter endast till PE-noder.
Eftersom vi vill segmentera våra användare med VN måste vi konfigurera VRF:er på PE-noderna. I topologin har jag tre VRF:er som heter RED, BLUE, and GREEN. Beroende på plattform kommer du att kunna ha tiotals om inte hundratals VRF:er utplacerade. Användare i VN RED kommer inte att kunna nå användare i VN BLUE eller GREEN.
I mitten har vi en P-router. Jag har adderat denna nod i topologin för att kunna förklara processen vid etikettbyte i MPLS-molnet, men också för att illustrera hur VRF-lite fungerar i ett senare avsnitt. Vi kunde ha utelämnat denna nod och kopplat de två PE:erna rygg mot rygg, men det finns med här för att illustrera tekniken.
I ritningen finns också förkortningarna:
- VPNv4
- LDP
Jag kommer att gå igenom var och en av dem eftersom de är centrala byggstenar i nätverk som tillhandahåller MPLS VPN-tjänster.
IP-nåbarhet mellan MPLS-noder är obligatorisk, vilket betyder att vi måste ha ett konfigurerat IGP-routningsprotokoll mellan PE- och P-routrar. I det här fallet har jag konfigurerat OSPF, men det kan vara vilken IGP som helst.
Etikettfördelning, distribution och vidarebefordran
Innan vi kan börja byta paket med hjälp av MPLS måste vi allokera och distribuera etiketter. En etikettrubrik ser ut så här:

Först har vi själva etiketten. Det kan tilldelas cirka 1 miljon etiketter (2^20 = 1 048 576). Därefter har vi tre bits för QoS-markeringar som kallas EXP, eller experimentella bits. En nyare term för detta är TC eller Traffic Class. ”S”-bits kommer att hänvisas till som ”Bottom of Stack”. Inställd (1) informerar den routern om att detta är den sista etiketten i stacken. Mer om detta senare. För att slutligen undvika ändlös looping av paket har vi en TTL som minskar per hopp precis, som vi är vana vid i IP.
Låt oss fokusera på P-noden i vår topologi ett tag. Eftersom MPLS-molnet inte känner till VN:erna behöver vi något annat än en IP-adress för att fatta beslut om vidarebefordran. Detta skulle vara en etikett. Faktum är att vi måste använda två etiketter för att MPLS VPN ska fungera:
- Toppetikett eller transportettikett
- Används för att vidarebefordra trafik till en specifik MPLS-router
- Bottenetikett eller VPN-etikett
- Används för att vidarebefordra trafik till ett specifikt prefix
Varje etikett har sin egen funktion eller betydelse. Två olika protokoll är ansvariga för att tilldela och distribuera dessa två etiketter:
- LDP (Label Distribution Protocol)
- Transportetikett
- BGP (Border Gateway Protocol)
- VPN-etikett
Vi börjar med att titta på LDP. En router som kör LDP kommer att tilldela en etikett per (IGP) prefix den känner till. Eftersom transportetiketten används för att ”nå den här routern” och vi kan ha flera gränssnitt som ansluter till andra P- och PE-noder, krävs något unikt för att routern ska kunna identifiera den mot MPLS-nätverket. För detta använder vi ett Loopback-gränssnitt. För PE03 har jag konfigurerat 3.3.3.3/32 på dess Loopback0-gränssnitt:
! PE03
interface Loopback0
ip address 3.3.3.3 255.255.255.255LDP
Liksom BGP är LDP ett TCP-baserat protokoll. Det fungerar lite som en IGP med dynamisk neighbor discovery och bygger sedan en TCP-session mellan peers för utbyte av etiketter:
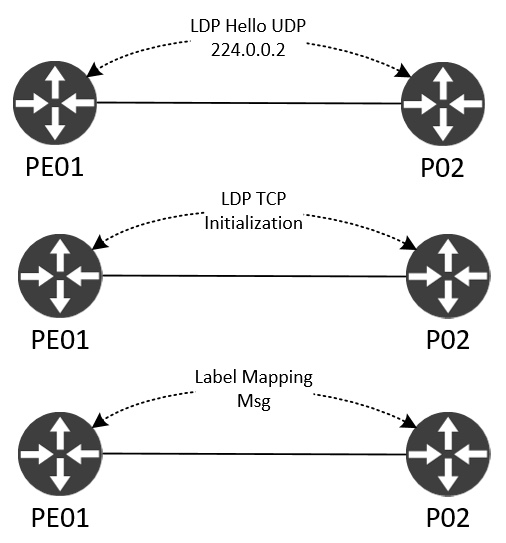
Ett Hello skickas ut med hjälp av alla routrars multicast-adress 224.0.0.2 med UDP/646. När LDP-routern ser en annan LDP-speaker’s LDP Hello startar den en trevägs TCP handshake och LDP-sessionen kan starta initieringen där bland annat version och timer förhandlas. Slutligen sker etikettutbytet med Label Mapping Messages. Om den här sker framgångsrikt mellan alla MPLS-noder finns nu end to end MPLS-nåbarhet. Det här lägger grunden för alla MPLS-aktiverade tjänster, såsom L3 VPN.
Eftersom de flesta företag redan kör BGP i sitt nätverk behöver du i praktiken bara addera LDP i nätverket, som är lätt att konfigurera och implementera, för att använda MPLS. Här kan du se konfigurationen som behövs för att aktivera LDP på en router:
! PE01, P02, PE03
mpls ldp router-id Loopback0 force
!
router ospf 1
mpls ldp autoconfigDet första kommandot tvingar LDP-router-id till Loopback0-gränssnittet. Det andra kommandot är en genväg för att aktivera LDP på alla OSPF-aktiverade gränssnitt, vilket är vad vi vill. Det är ett bra kommando, för när vi lägger till länkar behöver vi bara tänka på att konfigurera OSPF. Och det är vi vana vid! Båda dessa kommandon är mallkompatibla.
Med LDP-sessioner mellan PE01<->P02 och P02<->PE03 kan vi undersöka etiketterna som används för P03 av PE01 och P02:
! PE01
PE01#sh ip cef 3.3.3.3/32
3.3.3.3/32
nexthop 10.0.12.2 Ethernet0/0 label 200
PE01#
!
PE01#sh mpls forwarding 3.3.3.3
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
101 200 3.3.3.3/32 0 Et0/0 10.0.12.2
PE01#
! P02
P02#sh ip cef 3.3.3.3/32
3.3.3.3/32
nexthop 10.0.23.3 Ethernet0/1
P02#
!
P02#sh mpls forwarding 3.3.3.3
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
200 Pop Label 3.3.3.3/32 18414 Et0/1 10.0.23.3
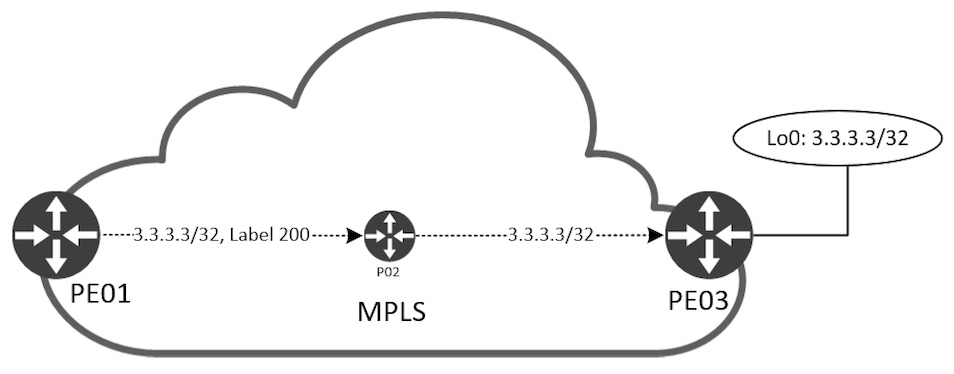
P02#PE1 använder etikett 200 och skickar paketet out its Eth0/0-gränssnitt för att nå 3.3.3.3/32, Loopback0 IP-adressen för PE03. P02 använder ingen etikett för att nå 3.3.3.3/32. Detta är inte fel, utan bara en optimering. Eftersom P02 är den sista routern innan den når PE03s Loopback0 IP, kan vi säkert ta bort (Pop) etiketten 200 och skicka ut paketet Etho/1 till PE03. Den här funktionen är praktisk när vi pratar om MPLS VPN. Jag kommer till det senare. För att skapa förståelse för ovanstående kommandoutgångar låt oss först visualisera etikett-tilldelningen som görs av LDP och sedan etikett-vidarebefordran mellan noderna.

PE03 börjar med att annonsera etikett 3 till P02 för sin Loopback0 IP, 3.3.3.3/32. Du kanske undrar varför vi inte såg etikett 3 i utgående etikett för P02 för 3.3.3.3/32. När PE03 skickar etikett 3 till PE02 säger den till P02 att ta bort (Pop) de paket som tagits emot för 3.3.3.3/32 innan de skickas till PE03. P02 tilldelar och annonserar också en etikett för 3.3.3.3/32 till PE01. Detta visas i den lokala etiketten för P02 på motsvarande sätt som utgående etikett på P01. Nu när PE01 skickar trafik till 3.3.3.3/32 adderar den till etiketten 200 och vidarebefordrar den till P02 som tar bort den och vidarebefordrar den (utan etikett) till PE03:
Vi kan till och med se detta om vi gör ett par captures när vi pingar mellan PE01 och PE03 Loopback0-gränssnitt.
P02 Eth0/0 (mot PE01):
 Vi ser etiketten 200, EXP är 0, S-bit är 1 som indikerar att detta är den sista etiketten och en TTL på 255.
Vi ser etiketten 200, EXP är 0, S-bit är 1 som indikerar att detta är den sista etiketten och en TTL på 255.
Paket som sett på PE03:s Eth0/0 (mot P02):
 Observera att när paketet tas emot på PE03 saknas MPLS-rubrik. Detta beror på pop action som gjordes på P02.
Observera att när paketet tas emot på PE03 saknas MPLS-rubrik. Detta beror på pop action som gjordes på P02.
Nu när vi har etablerat etikettväxling mellan våra MPLS-noder och förstår LDP kan vi titta på BGP.
BGP
För att få trafik från en endpoint till en annan krävs två etiketter. LDP tillhandahåller transport (topp)etiketten och BGP ansvarar för VPN-(nedre)etikett. Denna VPN-etikett definierar vårt VN-prefix. I det här nätverket har två Loopback10-gränssnitt konfigurerats i VN RED:
! PE01
interface Loopback10
vrf forwarding red
ip address 1.1.1.10 255.255.255.255
! PE03
interface Loopback10
vrf forwarding red
ip address 3.3.3.10 255.255.255.255BGP har en adressfamilj för MPLS VPN. Detta kallas VPNv4 för IPv4. Det finns även en för IPv6 som heter VPNv6. Funktionellt är det ingen skillnad. Vi behöver en etikett för ett prefix oavsett IP-protokollversion.
Eftersom vår P-nod saknar kunskap om VN:er behöver den inte köra BGP. Dess uppgift är att märka switchpaket med den övre etiketten – inget annat! Vi kan till och med kalla det en LSR (Label Switch Router). Det betyder att våra PE-noder måste ta emot VPNv4-uppdateringar. I den här enkla topologin har jag konfigurerat direct PE-till-PE BGP VPNv4-peerings:
! PE01
router bgp 123
bgp log-neighbor-changes
no bgp default ipv4-unicast
neighbor 3.3.3.3 remote-as 123
neighbor 3.3.3.3 update-source Loopback0
!
address-family vpnv4
neighbor 3.3.3.3 activate
neighbor 3.3.3.3 send-community extended
exit-address-family
!
address-family ipv4 vrf red
redistribute connected
exit-address-family
! PE03
router bgp 123
bgp log-neighbor-changes
no bgp default ipv4-unicast
neighbor 1.1.1.1 remote-as 123
neighbor 1.1.1.1 update-source Loopback0
!
address-family vpnv4
neighbor 1.1.1.1 activate
neighbor 1.1.1.1 send-community extended
exit-address-family
!
address-family ipv4 vrf red
redistribute connected
exit-address-familyNär du IOS-konfigurerar en neighbour under BGP-processen aktiveras adressfamiljen IPv4 unicast automatiskt. Jag har inaktiverat detta med no bgp standard ipv4-unicast eftersom det inte krävs för denna topologi. Peering mellan PE:erna sker i samma AS, vilket betyder att detta är en iBGP (intern BGP) peering i VPNv4-adressfamiljen. BGP-paket kommer från vårt Loopback0-gränssnitt som också kommer att användas som nästa hopp för BGP VPNv4-uppdateringar som skickas mellan peers. Slutligen the neighbor send-community extended behövs för att signalera vilket VN-medlemskap VPNv4-prefixet tillhör. När du aktiverar en neighbour under VPNv4 konfigurerar IOS detta automatiskt åt dig. Snyggt!
Lägg märke till adressfamiljen ipv4 vrf red-avsnittet. Det är här vi tar in prefix för BGP i VN RED. Specifikt har jag omdistribuerat de anslutna prefixen – Loopback10.
Eftersom vi kan ha många VN i ett MPLS VPN-nätverk och denna teknik även används för att segregera företag eller affärsenheter inom företag och gör att de kan använda en delad infrastruktur (vårt MPLS-moln), är överlappande IP-adresser i VN:erna möjligt. BGP VPNv4 gör att detta fungerar med en route distinguisher (RD). Även om detta är en BGP-funktion är den RD-konfigurerad enligt definitionen av VRF i IOS:
! PE01
vrf definition red
rd 1.1.1.1:10
!
address-family ipv4
route-target export 123:10
route-target import 123:10
exit-address-family
! PE03
vrf definition red
rd 3.3.3.3:10
!
address-family ipv4
route-target export 123:10
route-target import 123:10
exit-address-familyI detta exempel har jag använt Loopback0 IP colon a numret för att konfigurera RD:n. För PE01 är detta värde 1.1.1.1:10 för VN RED. Varje konfigurerad VN måste ha en unik RD per VN. Det är möjligt att konfigurera RD med ett värde på BGP ASN colon nummer istället. För- och nackdelar med detta är irrelevanta här.
Inom VRF har vi också något som kallas route-targets, eller RT. Detta värde konfigureras med BGP ASN colon nummer, men kan också konfigureras med ett IP-colon nummer precis som RD:n. Återigen, jag kommer inte att diskutera för- och nackdelar med detta. Det som är viktigt att förstå med RT är att detta nummer bestämmer vår policy för import och export av prefix till och ut ur VN! Låt mig illustrera hur denna process fungerar tillsammans med BGP VPNv4:
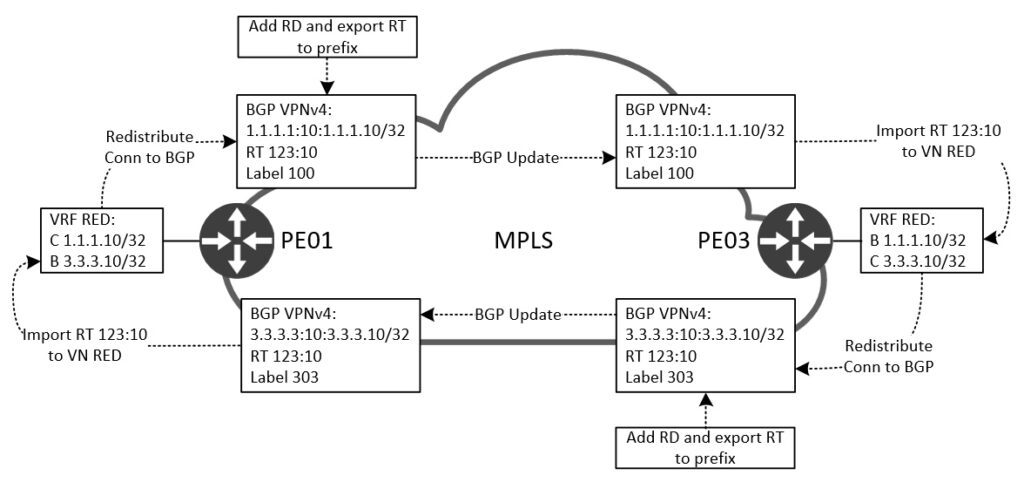
Om vi börjar med att titta på PE03. Här har vi en routingtabell för VN RED som består av en ansluten (C) route för prefix 3.3.3.10/32. Detta prefix omdistribueras till BGP som vi såg i BGP-konfigurationen ovan. När vi gör detta kommer BGP att skapa ett VPNv4-prefix som består av RD colon prefixet:
PE03#sh bgp vpnv4 u vrf red 3.3.3.10/32
BGP routing table entry for 3.3.3.3:10:3.3.3.10/32, version 2
Paths: (1 available, best #1, table red)
Advertised to update-groups:
1
Refresh Epoch 1
Local
0.0.0.0 from 0.0.0.0 (3.3.3.3)
Origin incomplete, metric 0, localpref 100, weight 32768, valid, sourced, best
Extended Community: RT:123:10
mpls labels in/out 303/nolabel(red)
rx pathid: 0, tx pathid: 0x0
PE03#Lägg märke till den första raden där det går att läsa 3.3.3.3:10:3.3.3.10/32 som är vårt VPNv4-prefix. Eftersom varje VN har sin egen RD kan prefixet 3.3.3.10/32 användas i alla VN utan att kollidera med varandra. Titta också på RT:123:10 som är vår (export) routetarget som är konfigurerad under VRF. Slutligen ser vi en VPN-etikett 303, som lades till av BGP VPNv4. Nu när VPNv4-prefixet har skapats med de MPLS VPN-byggstenar som behövs, kan vi vidarebefordra uppdateringen till den andra PE01. Här kommer routern att kontrollera RT och importera detta prefix till sin VN RED routingtabell. Etiketten 303 kommer också att användas av PE03 för att fatta beslut om vidarebefordran när ett paket med det här datavärdet tas emot.
Precis som PE03 annonserade en rutt för 3.3.3.10/32, kommer PE01 att annonsera sin anslutna rutt i VN RED, 1.1.1.10/32, till PE03. Här används etiketten 100.
Här är en visualisering av etikettvidarebefordran som sker när PE01 skickar trafik i VN RED till 3.3.3.10 ”bakom” PE03:
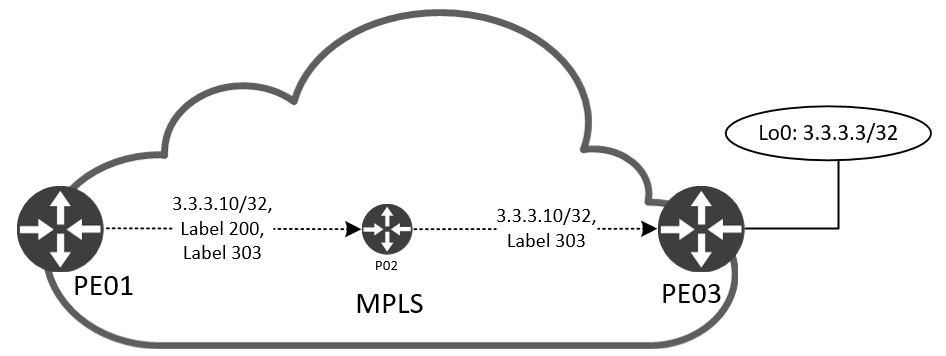
Vi kan verifiera detta genom att titta på CEF för VN RED vid varje hopp:
! PE01
PE01#sh ip cef vrf red 3.3.3.10
3.3.3.10/32
nexthop 10.0.12.2 Ethernet0/0 label 200 303
PE01#
! P02
P02#sh mpls forwarding-table labels 200
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
200 Pop Label 3.3.3.3/32 1359 Et0/1 10.0.23.3
P02#
! PE03
PE03#sh mpls forwarding-table labels 303
Local Outgoing Prefix Bytes Label Outgoing Next Hop
Label Label or Tunnel Id Switched interface
303 Pop Label 3.3.3.10/32[V] 0 aggregate/red
PE03#
!
PE03#sh ip cef vrf red 3.3.3.10
3.3.3.10/32
receive for Loopback10
PE03#På PE01, ingångs PE-routern, tittar vi i CEF-tabellen för VN RED och ser en etikettstack bestående av två etiketter. Den första, 200, är vår transportetikett. Den andra, 303, är vår VPN-etikett. Paketet out Eth0/0 skickas mot P02. Här utförs en etikettsökning (kom ihåg att P-noden fattar beslut om vidarebefordran baserat på etiketter och inte IP:er). Etiketten 200 måste tas bort från stapeln och sedan skicka paketet out Eth0/1 mot PE03, vår egress PE. Vid PE03 är den enda etiketten kvar i paketet 303 som tilldelas av PE03 själv, vilket betyder att den vet vilket prefix och VRF denna etikett motsvarar och vi kan se att det är den mottagande routern för detta prefix på dess Loopback10-gränssnitt.
Låt mig fördjupa kunskapen genom att visa dig paketfångningarna:
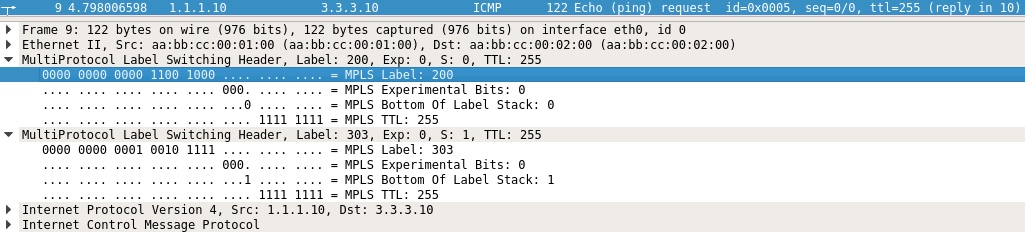 Taken ingress on P02 from PE01. Här ser vi vår stack med de den första (topp/transport) 200-etiketten. Detta är etiketten som tilldelats och distribueras av P02 till PE01 för att nå PE03:s Loopback0 IP. Den nedersta (VPN) etiketten är 303 med S-biten inställd (som betyder sista etiketten).
Taken ingress on P02 from PE01. Här ser vi vår stack med de den första (topp/transport) 200-etiketten. Detta är etiketten som tilldelats och distribueras av P02 till PE01 för att nå PE03:s Loopback0 IP. Den nedersta (VPN) etiketten är 303 med S-biten inställd (som betyder sista etiketten).
 Vid PE03 ser vi att det bara finns en etikett i paketet. Detta beror på det faktum att P02 Pops den övre etiketten (200) innan paketet vidarebefordras till den sista hop-routern, eller egress PE, PE03. Det här är en optimering som hjälper PE03 att bara göra en etikettsökning istället för två. Smart.
Vid PE03 ser vi att det bara finns en etikett i paketet. Detta beror på det faktum att P02 Pops den övre etiketten (200) innan paketet vidarebefordras till den sista hop-routern, eller egress PE, PE03. Det här är en optimering som hjälper PE03 att bara göra en etikettsökning istället för två. Smart.
Jag har inte visat dig hur routingtabellen ser ut med MPLS VPN, eftersom fokus fram till denna punkt var att förklara signaleringen och vidarebefordran. Ta en titt på routingtabellen för PE01 för VN RED:
! PE01
PE01#sh ip route vrf red | be ^Gateway
Gateway of last resort is not set
1.0.0.0/32 is subnetted, 1 subnets
C 1.1.1.10 is directly connected, Loopback10
3.0.0.0/32 is subnetted, 1 subnets
B 3.3.3.10 [200/0] via 3.3.3.3, 02:02:04
PE01#
PE01#sh ip route vrf red 3.3.3.10
Routing Table: red
Routing entry for 3.3.3.10/32
Known via "bgp 123", distance 200, metric 0, type internal
Last update from 3.3.3.3 02:02:17 ago
Routing Descriptor Blocks:
* 3.3.3.3 (default), from 3.3.3.3, 02:02:17 ago
Route metric is 0, traffic share count is 1
AS Hops 0
MPLS label: 303
MPLS Flags: MPLS Required
PE01#
Lägg märke till nästa hopp av den BGP (B) inlärda routen till 3.3.3.10/32. Detta är IP:n för P03:s Loopback0-gränssnitt, eller PE03:s BGP-uppdateringskälla. Detta kommer att vara fallet för alla prefix i alla VN som PE03 annonserar nåbarhet mot. Genom att titta på vår vidarebefordrantabell, CEF, löser vi nästa hopp och tar etikettinformationen tillsammans med ett utgående gränssnitt för att se hur routern faktiskt vidarebefordrar trafik till denna destination.
Vid det här laget borde du ha en god grundläggande förståelse för MPLS VPN, dess byggstenar, rubriker, signalering och vidarebefordran. Nu kan vi prata mer om VRF-lite.
VRF-lite
Begreppet VRF-lite betyder helt enkelt att vi implementerar VRF-baserad segmentering i vårt nätverk utan att använda MPLS. Med VRF-lite har vi inte längre fördelen av att kunna abstrahera sammankopplingen (molnet) mellan ändpunkts-gateways (MPLS PE-noder) som vi kunde i MPLS-exemplet ovan. Med detta menar jag att nu måste vi konfigurera VRF:er vid varje hopp mellan alla våra routrar. Detta betyder mer handpåläggning när nätverket byggs ut och påverkar skalbarheten. Låt mig demonstrera…

Eftersom vi inte har något protokoll för att skilja mellan VN:erna på länkarna mellan routrarna måste vi antingen addera fler fysiska länkar eller implementera en annan form av virtualisering. Det är inte särskilt genomförbart att bara lägga till fler länkar, så låt oss titta på att virtualisera länkarna vi har för att separera trafiken. För detta använder vi VLAN-taggar. VLAN kommer att isolera VN från varandra i dataplanet, men vi måste fortfarande utbyta routinginformation. Ett VRF-medvetet kontrollplansprotokoll behövs per hopp. I det här exemplet använder jag OSPF, men i teorin kan det vara vilket routingprotokoll som helst – inklusive BGP.
Nedan är konfigurationen av VN RED med VRF-lite för alla tre routrarna.
! R01
vrf definition red
!
address-family ipv4
exit-address-family
!
!
interface Ethernet0/0
no ip address
!
interface Ethernet0/0.10
encapsulation dot1Q 10
vrf forwarding red
ip address 10.10.12.1 255.255.255.0
ip ospf network point-to-point
ip ospf 10 area 0
!
interface Loopback10
vrf forwarding red
ip address 1.1.1.10 255.255.255.255
ip ospf 10 area 0
!
router ospf 10 vrf red
! R02
vrf definition red
!
address-family ipv4
exit-address-family
!
!
interface Ethernet0/0
no ip address
!
interface Ethernet0/0.10
encapsulation dot1Q 10
vrf forwarding red
ip address 10.10.12.2 255.255.255.0
ip ospf network point-to-point
ip ospf 10 area 0
!
interface Ethernet0/1
no ip address
!
interface Ethernet0/1.11
encapsulation dot1Q 11
vrf forwarding red
ip address 10.10.23.2 255.255.255.0
ip ospf network point-to-point
ip ospf 10 area 0
!
interface Loopback10
vrf forwarding red
ip address 2.2.2.10 255.255.255.255
ip ospf 10 area 0
!
router ospf 10 vrf red
! R03
vrf definition red
!
address-family ipv4
exit-address-family
!
!
interface Ethernet0/0
no ip address
!
interface Ethernet0/0.11
encapsulation dot1Q 11
vrf forwarding red
ip address 10.10.23.3 255.255.255.0
ip ospf network point-to-point
ip ospf 10 area 0
!
interface Loopback10
vrf forwarding red
ip address 3.3.3.10 255.255.255.255
ip ospf 10 area 0
!
router ospf 10 vrf red
Nu måste vi upprätthålla en VLAN- och IP-plan för alla konfigurerade VN – för varje L3-hopp/router i nätverket! En ny routinginstans måste också konfigureras per VN.
Låt oss snabbt se innehållet i routingtabellen och vidarebefordrantabellen (CEF) för R01:
! R01
R01#sh ip route vrf red | be ^Gateway
Gateway of last resort is not set
1.0.0.0/32 is subnetted, 1 subnets
C 1.1.1.10 is directly connected, Loopback10
2.0.0.0/32 is subnetted, 1 subnets
O 2.2.2.10 [110/11] via 10.10.12.2, 00:26:53, Ethernet0/0.10
3.0.0.0/32 is subnetted, 1 subnets
O 3.3.3.10 [110/21] via 10.10.12.2, 00:26:53, Ethernet0/0.10
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
C 10.10.12.0/24 is directly connected, Ethernet0/0.10
L 10.10.12.1/32 is directly connected, Ethernet0/0.10
O 10.10.23.0/24 [110/20] via 10.10.12.2, 00:26:53, Ethernet0/0.10
R01#
R01#sh ip cef vrf red 3.3.3.10
3.3.3.10/32
nexthop 10.10.12.2 Ethernet0/0.10
R01#
Som ni kan se är VRF-lite tillvägagångssätt platt och innehåller därför en hel del replikerad konfiguration som vi måste dokumentera för varje hopp för att kunna hålla en överblick över nätverket och för att kunna felsöka det.
MPLS VPN- jämfört med VRF-lite
Om du adderar 10 eller 20 VRF:er till ett nätverk som kör VRF-lite kommer du att känna av belastningen på både dig och nätverksnoderna.
Jag vet att nätverket skulle vara ”enklare” med VRF-lite, eftersom vi inte har det extra lagret av etiketter inblandade. Men närhelst du utökar nätverket måste du konfigurera alla VN:er på varje länk och nod du lägger till. Och när du tittar på nästa hopp efter ett prefix i routingtabellen kommer detta att vara ett per-VN nästa hopp och inte BGP-uppdateringskällan.
Den mest utmanande delen av MPLS VPN är att förstå tekniken och dess byggstenar. Om du redan är bekant med BGP handlar det här i realiteten bara om LDP. Vi adderar bara ett protokoll till nätverket och plötsligt kan vi skala och ta bort massor av kontrollplanstillstånd för transitroutrarna i vårt nätverk. Att tillhandahålla ett nytt VN handlar bara om att konfigurera PE-noderna, vilket innebär att vi inte riskerar att felkonfigurera våra viktiga P-noder. Om det saknas P-noder behöver vi inte konfigurera något mellan PE-noderna – BGP säkerställer att de nya VN och dess prefix tilldelas de nödvändiga etiketterna dynamiskt för att kunna vidarebefordra trafik på befintliga länkar i vårt MPLS-moln. Detta tillvägagångssätt minskar verkligen den konfiguration och handpåläggningen som krävs för att distribuera och underhålla ett sådant nätverk.
Enligt min mening överväger fördelarna med att använda MPLS vida enkelheten med att använda VRF-lite. Och nu när du vet hur MPLS VPN fungerar, hoppas jag innerligt att du inte är rädd för att testa och kanske överväger att implementera det i ditt nätverk – om tillämpligt.
Tack för att du läser detta inlägg. Jag hoppas att du tyckte om det!
